Python BQ scripts
I've written several Python scripts to help parse and handle scripture material. Once you have raw access to the scripture text, you can do all sorts of fun analysis.
- Scraping Scripture Text
- Creating Quoting Bee Lists
- Creating an "of" list
- Creating unique first-word lists
Scraping Scripture Text
Because of NIV copyright, I can't share the full scripture text. However, I can share a tool that will help you generate your own copy of the scripture text. The result of the below script is a compressed pickle'd format, which is easy to unpack and parse in other Python scripts.
It legally scrapes an online source, which can only be used for personal use. You can still share lists that you derive from the text, but not the full text itself.
# scrape niv books from biblegateway.com for personal use only # you are responsible for following niv copyright # unpack using pickle in other scripts # released gplv3 by jeffrey sharkey import re, pycurl, pickle, StringIO, time #import zipfile # set the books you want to pull down # default set is gepcp books = [55,56,57,58,64] def fetch(url): raw = StringIO.StringIO() curl = pycurl.Curl() curl.setopt(curl.URL, url) curl.setopt(curl.USERAGENT, 'Mozilla/5.0 (X11; U; Linux i686; en-US; rv:1.8.1.12) Gecko/20080209 Firefox/2.0.0.12') curl.setopt(curl.WRITEFUNCTION, raw.write) curl.setopt(curl.FOLLOWLOCATION, 1) curl.perform() curl.close() return raw.getvalue() redead = re.compile('No results found',re.I|re.S|re.M) rechapter = re.compile('<h4>([^<]+)</h4>',re.I|re.S|re.M) resection = re.compile('<h5>([^<]+)</h5>.*?<span.+?class="sup">([^<]+)</span>',re.I|re.S|re.M) reverse = re.compile('<span.+?class="sup">([^<]+)</span>([^<]+)',re.I|re.S|re.M) refootnote = re.compile('<sup>.+?</sup>',re.I|re.S|re.M) #pickled = StringIO.StringIO() pickled = open('scraped.txt', 'w') # for each book continue pulling down chapters until error for book in books: chapnum = 0 while True: chapnum += 1 print "fetching chapter=%d of book=%d" % (chapnum, book) raw = fetch("http://www.biblegateway.com/passage/?book_id=%s&chapter=%s&version=31" % (book, chapnum)) if redead.search(raw): print "\tchapter doesnt exist, moving to next book" break # strip out all footnotes and identify chapter raw = refootnote.sub("", raw) chapter = rechapter.search(raw).group(1) # pull out all section titles and verses sections = resection.findall(raw) verses = reverse.findall(raw) # save all scraped information for later use pickle.dump(chapter, pickled) pickle.dump(sections, pickled) pickle.dump(verses, pickled) print "\tfound sections=%d and verses=%d" % (len(sections), len(verses)) time.sleep(2) # pack up all saved chapters #save = zipfile.ZipFile('scraped.zip', 'w', zipfile.ZIP_DEFLATED) #save.writestr('scraped.txt', pickled.getvalue()) #save.close() pickled.close() print "done, all scraped data available in scraped.txt"
Creating Quoting Bee Lists
Quoting bees are fun, but generating the lists can be painful. This Python script automatically builds a PDF while following rules, such as minimum and maximum word-count for verses, and minimum distance between verses. It assumes that you've built the scripture text library using the script above.

The reportlib library is quite flexible, and you could format the quoting bee output in any way you'd like with only slight code editing.
# build a quoting bee list # released gplv3 by jeffrey sharkey pageheader = 'Set A-1: GEPCP verses 25-40 words long, at least 100 verses apart' numverses = 30 # number of verses for the list minlen = 25 # minimum verse length in words maxlen = 40 # maximum verse length in words distance = 100 # minimum distance between two consecutive verse import pickle, re, random from reportlab.lib import units, pagesizes, colors, styles from reportlab.platypus import Table, TableStyle from reportlab.platypus import SimpleDocTemplate, Paragraph pickled = open("scraped.txt") collection = [] actual = 0 wordbound = re.compile("[^A-Za-z1-9]+",re.I|re.S|re.M) # unpack all verses try: while True: chapter = pickle.load(pickled) sections = pickle.load(pickled) verses = pickle.load(pickled) for verse in verses: # make sure that this verse is within word counts actual += 1 words = len(wordbound.findall(verse[1]))+1 if words < minlen or words > maxlen: continue reference = "%s:%s" % (chapter, verse[0]) collection.append((actual, reference, verse[1])) except: pass print "only %d of %d verses met your length requirements" % (len(collection), actual) # make random selection of verses verses = [] lastactual = -distance while len(verses) < numverses: # pick a random verse from those remaining picked = random.randint(0, len(collection)-1) # check to make sure we have enough distance thisactual = collection[picked][0] if abs(lastactual - thisactual) < distance: continue lastactual = thisactual # insert selected verse and remove from list verses.append(collection.pop(picked)) # do actual printing margin = 0.5*units.inch width = pagesizes.letter[0]-(margin*2) def header(canvas, doc): global margin canvas.saveState() canvas.setFont('Times-Bold',11) canvas.drawString(margin, pagesizes.letter[1] - margin*1.2, pageheader) canvas.drawString(margin, margin, "Page %d" % (doc.page)) canvas.restoreState() # convert verses into pdf paragraphs style = styles.getSampleStyleSheet()["Normal"] style.leading = style.leading*1.3 verses = map(lambda verse: (verse[1], Paragraph(verse[2], style)), verses) # build pdf table style = TableStyle() style.add('VALIGN', (0,0), (-1,-1), 'TOP') style.add('GRID', (0,0), (-1,-1), 1, colors.black) table = Table(verses, [width*0.2,width*0.8]) table.setStyle(style) # build pdf output doc = SimpleDocTemplate("quotingbee.pdf", pagesize=pagesizes.letter, topMargin=margin*1.5, leftMargin=margin, bottomMargin=margin*1.5, rightMargin=margin) doc.build([table], onFirstPage=header, onLaterPages=header)
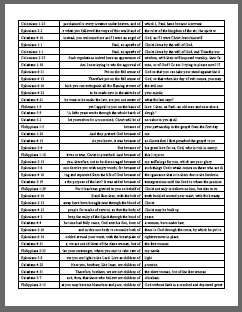
Creating an "of" list
There are quite a few words omitted from the official concordance which can be useful to study. One of the biggest requests is creating an "of list" that has all phrases of the type "... of something" or "something of ...".
This script uses the scripture text generated earlier to create these "of" lists for your own study use when creating lists. It could easily be adapted to build an entire concordance by running over each word.
# build an "of" list from the scripture text # released gplv3 by jeffrey sharkey import pickle, re, codecs from reportlab.lib import units, pagesizes, colors, styles from reportlab.platypus import Table, TableStyle from reportlab.platypus import SimpleDocTemplate, Paragraph pickled = open('scraped.txt', 'r') reword = re.compile('\\b(\\w+)\\b( of )\\b(\\w+)\\b',re.I|re.S|re.M) dashes = re.compile('\xe2\x80\x94') collection = [] # unpack all verses, keeping track of all "of" references try: while True: chapter = pickle.load(pickled) sections = pickle.load(pickled) verses = pickle.load(pickled) for verse in verses: numb, text = verse text = dashes.sub("--", text) reference = "%s:%s" % (chapter, numb) # for this verse, find each "of" reference start = 0 while True: match = reword.search(text, start) if match is None: break start = match.start()+1 before = text[0:match.start()] preword = match.group(1) word = match.group(2) postword = match.group(3) after = text[match.end():-1] collection.append((reference, before, preword, word, postword, after)) except: pass # build prefix and postfix lists prefix = map(lambda ref: (ref[2], ref[1], ref[3], ref[4], ref[5], ref[0]), collection) postfix = map(lambda ref: (ref[4], ref[5], ref[3], ref[2], ref[1], ref[0]), collection) prefix.sort() postfix.sort() # do actual printing margin = 0.5*units.inch width = pagesizes.letter[0]-(margin*2) # convert verses into pdf paragraphs style = styles.getSampleStyleSheet()["Normal"] prefixprint = map(lambda ref: (ref[5], (ref[1]+ref[0]+ref[2])[-50:-1], (' '+ref[3]+ref[4])[1:50]), prefix) postfixprint = map(lambda ref: (ref[5], (ref[4]+ref[3]+' ')[-50:-1], (ref[2]+ref[0]+ref[1])[1:50]), postfix) # build pdf table def buildTable(data): style = TableStyle() style.add('VALIGN', (0,0), (-1,-1), 'TOP') style.add('GRID', (0,0), (-1,-1), 1, colors.black) style.add('ALIGN', (1,0), (1,-1), 'RIGHT') table = Table(data, [width*0.2,width*0.4,width*0.4]) table.setStyle(style) return table # build pdf output doc = SimpleDocTemplate("prefixlist.pdf", pagesize=pagesizes.letter, topMargin=margin, leftMargin=margin, bottomMargin=margin, rightMargin=margin) doc.build([buildTable(prefixprint)]) doc = SimpleDocTemplate("postfixlist.pdf", pagesize=pagesizes.letter, topMargin=margin, leftMargin=margin, bottomMargin=margin, rightMargin=margin) doc.build([buildTable(postfixprint)])
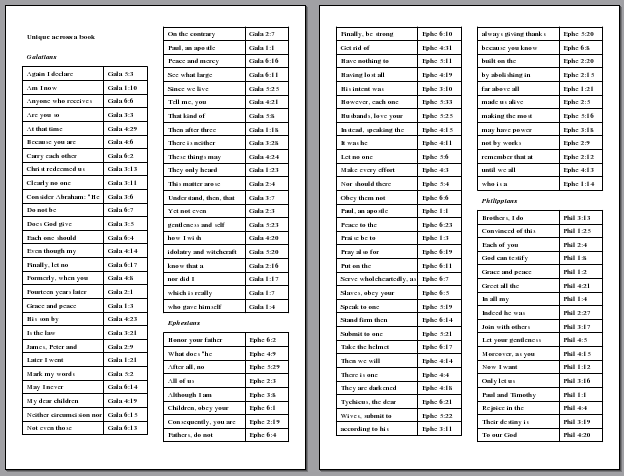
Creating unique first-word lists
Quotation completion questions are usually pretty easy if you know the scripture text, but at higher levels of competition some question writers can choose to leave out any contextual information. There could be a quotation completion over all of the material, which means you need to know all the verses that have unique first-words.
This script creates a list of unique first-word verses at a variety of levels. First, the list of all 76 verses across the entire scripture text that have unique first-words. Then, to show the power of the script, we create the unique first-word lists for each book, chapter, and section title.
Only the first three words of each verse are included, because they are usually enough to link to the correct verse. This script also shows how we can change the page size to fold and fit nicely inside a quiz book--when printing be sure to print two-to-a-page. It also shows how easy it is to create two-column lists.
# build list of unique verses across books, book, chapters, and sections # released gplv3 by jeffrey sharkey import pickle, re from reportlab.lib import units, pagesizes, colors, styles from reportlab.platypus import Table, TableStyle, Spacer, Paragraph, Frame from reportlab.platypus import BaseDocTemplate, PageTemplate, NextPageTemplate, PageBreak pickled = open("scraped.txt") refirstword = re.compile('(\\w+)\\b',re.I|re.S|re.M) rechapter = re.compile('(\\d+)',re.I|re.S|re.M) redashes = re.compile('\xe2\x80\x94') refirstthree = re.compile('(\\w+[^\\w]+\\w+[^\\w]+\\w+)[^\\w]',re.I|re.S|re.M) # a grouping of verses class Group: def __init__(self, name): self.name = name self.firstwords = {} # report seeing a firstword and verse in this group def reportword(self, firstword, verse): if not self.firstwords.has_key(firstword): self.firstwords[firstword] = [] self.firstwords[firstword].append(verse) # strip our entire list of firstwords down to only unique ones def makeunique(self): self.firstwords = dict([ (firstword,verses) for firstword,verses in self.firstwords.items() if len(verses)==1]) if len(self.firstwords) == 0: return None return self # return a sorted list for later printing def printable(self): set = [verses[0] for firstword,verses in self.firstwords.items()] set.sort() set = map(lambda verse: (refirstthree.search(verse[0]).group(1), verse[1]), set) return set books = []; chapters = []; sections = [] entiretext = Group('Entire text') thisbook = Group(None); thischapter = Group(None); thissection = Group(None) # unpack all verses, counting up the firstword of each verse try: lastbookname = None while True: chapter = pickle.load(pickled) sectionlist = pickle.load(pickled) verses = pickle.load(pickled) # we know we are walking over a chapter boundary chapters.append(thischapter.makeunique()) thischapter = Group(chapter) # check if this chapter walks over a book boundary bookname = rechapter.sub("", chapter) chapnum = rechapter.search(chapter).group(1) if not bookname == lastbookname: books.append(thisbook.makeunique()) thisbook = Group(bookname) lastbookname = bookname for verse in verses: numb, text = verse text = redashes.sub("--", text) reference = "%s %s:%s" % (bookname[0:4], chapnum, numb) fullverse = (text, reference) # check if this verse walks over a section boundary for section in sectionlist: if numb == section[1]: sections.append(thissection.makeunique()) thissection = Group(section[0]) # count up this firstword in various contexts firstword = refirstword.search(text).group(1).lower() entiretext.reportword(firstword, fullverse) thisbook.reportword(firstword, fullverse) thischapter.reportword(firstword, fullverse) thissection.reportword(firstword, fullverse) except: pass # save any trailing groups books.append(thisbook.makeunique()) chapters.append(thischapter.makeunique()) sections.append(thissection.makeunique()) entiretext.makeunique() # do actual printing halfsheet = (pagesizes.letter[1]/2, pagesizes.letter[0]) margin = 0.3*units.inch width = (halfsheet[0]-(margin*3))/2 def maketable(printable): style = TableStyle() style.add('VALIGN', (0,0), (-1,-1), 'TOP') style.add('GRID', (0,0), (-1,-1), 1, colors.black) table = Table(printable, [width*0.65,width*0.35]) table.setStyle(style) return table def maketitle(document, title): style = styles.getSampleStyleSheet()["Normal"] document.append(Spacer(0, margin/3)) document.append(Paragraph('<b>%s</b>' % (title), style)) document.append(Spacer(0, margin/3)) document = [] maketitle(document, "Unique across entire scripture text") document.append(maketable(entiretext.printable())) def dumpset(title, set): document.append(PageBreak()) maketitle(document, title) for item in set: if item is None: continue maketitle(document, '<i>%s</i>' % (item.name)) document.append(maketable(item.printable())) dumpset("Unique across a book", books) dumpset("Unique across a chapter", chapters) dumpset("Unique across a section", sections) # build pdf output doc = BaseDocTemplate("unique.pdf", pagesize=halfsheet, topMargin=margin, leftMargin=margin, bottomMargin=margin, rightMargin=margin) # make default two-column output frame1 = Frame(doc.leftMargin, doc.bottomMargin, width, doc.height, id='col1') frame2 = Frame(doc.leftMargin+width+margin, doc.bottomMargin, width, doc.height, id='col2') doc.addPageTemplates([PageTemplate(id='twocolumn',frames=[frame1,frame2])]) doc.build(document)